MapReduce的工作流程
MapReduce 的处理过程可以理解为 Input -> map -> map-shuffle -> reduce-shuffle -> reduce -> output 几个阶段,如下图所示。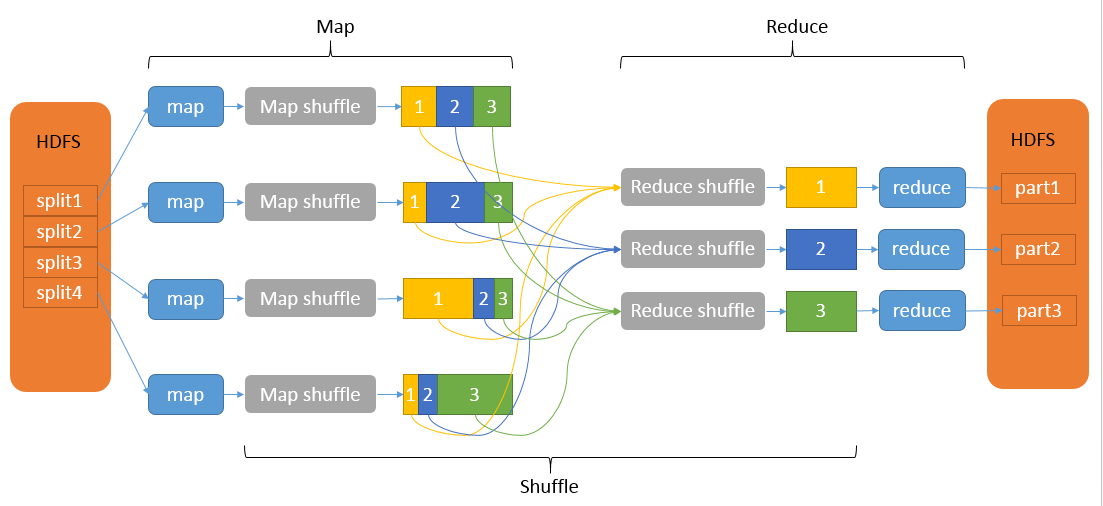
Input 阶段(主要是切片 split 过程)
该阶段简述流程:
切片是逻辑上的,抽象为inputSpilt接口,包含一个以字节为单位的切片大小及一组切片存储位置。每个切片封装成一个FileSpilt对象(inputSpilt接口的实现类),FileInputFormat覆盖了InputFormat的getSplits()方法,将一个大文件切分计算,并返回一个切片列表,并根据切片的大小进行排序,优先处理大的切片。
切片的具体流程:
① 通过listStatus(job)获取客户端输入的文件列表,并返回一个List<FileStatus>文件列表。FileStatus类是对文件信息(属性,块的大小等信息)的一个包装类。
② 从文件列表中取一个文件 —- 计算切片的大小,位置信息。splitsSize=Math.max(minSize, Math.min(maxSize, blockSize)),其中minSize最小切片大小为1个字节,maxSize默认为 long 的最大值,blockSize默认为128M。
③ 根据splitsSize将文件切分,如果切分的时候,剩余部分不大于splitSize * 1.1且大于 0B,将会该区域作为一个切片,防止一个map处理的数据太小。
④ 将切片加入到List<InputSplits> splits集合中。
⑤ 重复 ② ③ ④ 迭代处理每一个文件。
⑥ 所有文件切完成后,返回切片集合splits。
Map阶段
① Map任务把输入的切片传给InputFormat(默认实现类FileInputFormat -> TextInputFormat)的createReordReader()返回一个RecordReader(LineRecordReader),然后通过它的成员变量(SplitLineReader)的readLine()方法读取数据并生成 Key-Value键值对,保存在RecordReader读取器中,通过它的成员方法getCurrentKey()和getCurrentValue获取。
② 将读取的Key-Value键值对传送给map()方法,作为参数执行用户自定义的map()逻辑。
PS:在读取数据时,如果不是第一个片,总是扔掉切片的第一行数据,因为每次读取总是(除了最后一片)多读下一个片的第一行。目的是防止同一行数据分割到两片中,如下图所示。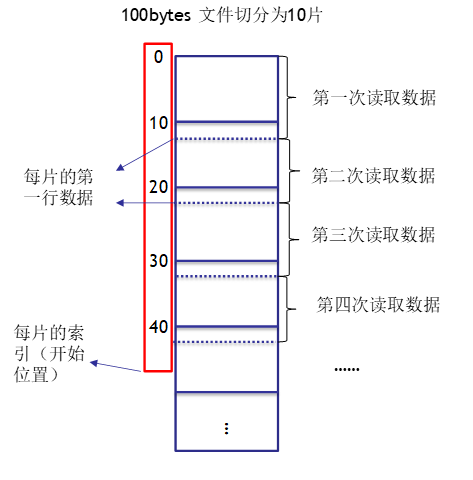
Map端的shuffle:
分区 -> 写入环形内存缓冲区 -> 溢出写出 -> 归并,如下图所示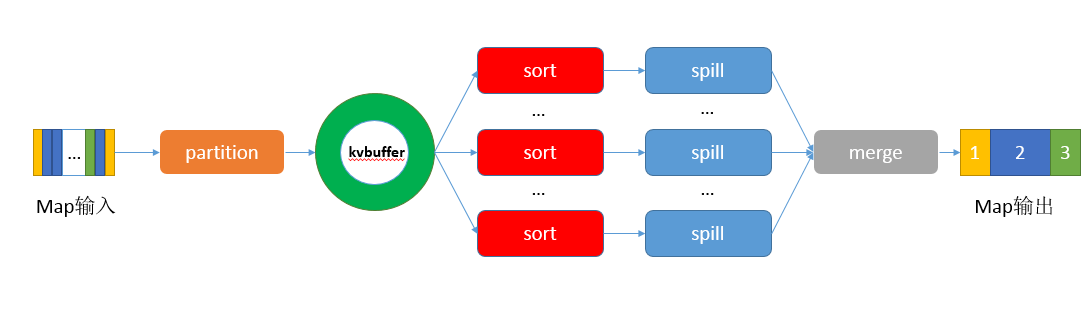
① 经过map()函数处理后得到的 Key-Value 键值对写入缓冲区之前,需要先进行分区操作(map任务处理的结果发送到指定的reducer上执行。
② context.write()被调用时,MapOutputCollector会将map()的输出结果写入到环形缓冲区(默认大小100MB)。
③ 当环形缓冲区到达设置的阈值(80%)后,会锁定这80%的内存,便在每个分区中对其中的Key-Value键值对按照键Key进行排序(快速排序或自定义排序),排序的结果为缓冲区内的数据按照Partition为单位聚集在一起,同一个Partition内的数据按照Key进行排序。排序完成后会溢写成小文件,然后开启一个后台线程将这部分数据以临时文件的方式溢写到本地磁盘中。(若客户端定义了combiner,则会在分区排序后到溢写出前自动调用combiner,将相同的key的value相加,减少溢写到磁盘的数据量),剩余的20%的内存在此期间可以继续写入map输出的键值对。溢出写过程按轮询方式将缓冲区中的内容写到mapreduce.cluster.local.dir属性指定的目录中。
④ 当溢出的小文件过多时,就会将多个小文件进行归并(排序)生成一个已分区和排序的大文件。
Reduce端的shuffle:
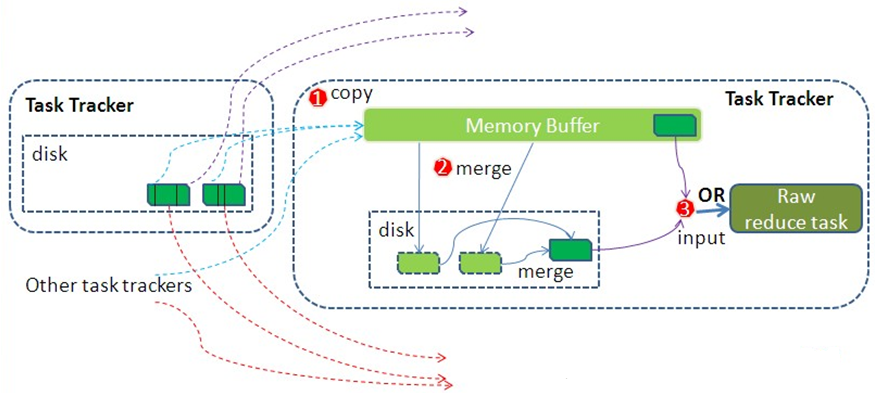
① Reduce进程启动一些数据copy线程,通过HTTP请求Map Task所在的NodeManager复制某一分区的数据文件放进内存缓冲区中。一般需要从多Map Task 复制数据,有一个Map Task完成,便开始复制。
② 一般需要从多Map Task 复制数据, 如果内存缓冲区中能放得下这次数据的话就直接把数据写到内存中;如果内存缓冲区中放不下,到达缓冲区的阈值后,会merge合并溢出到磁盘。如果自定义了combiner,则在合并期间运行,降低写入磁盘的数据量。
③ 再将缓冲区中的数据(或)和磁盘中的数据作为Reduce端的输入。
Reduce阶段
① 根据GroupingConparator()进行分组(默认使用键分组,也可以自定义分组器),并将每组数据发送给reduce(key,iterator),(一组的数据值合并在一起,使用一个迭代器获取,只取第一个数据的key)。
② 调用context.writer()方法后,执行OutputFormat(默认为FileOutputFormat -> TextOutputFormat)的getRecordWriter()方法,返回一个RecordWriter(LineRecordWriter),然后调用writer()将处理结果写到HDFS等文件系统。
环形缓冲区的底层实现
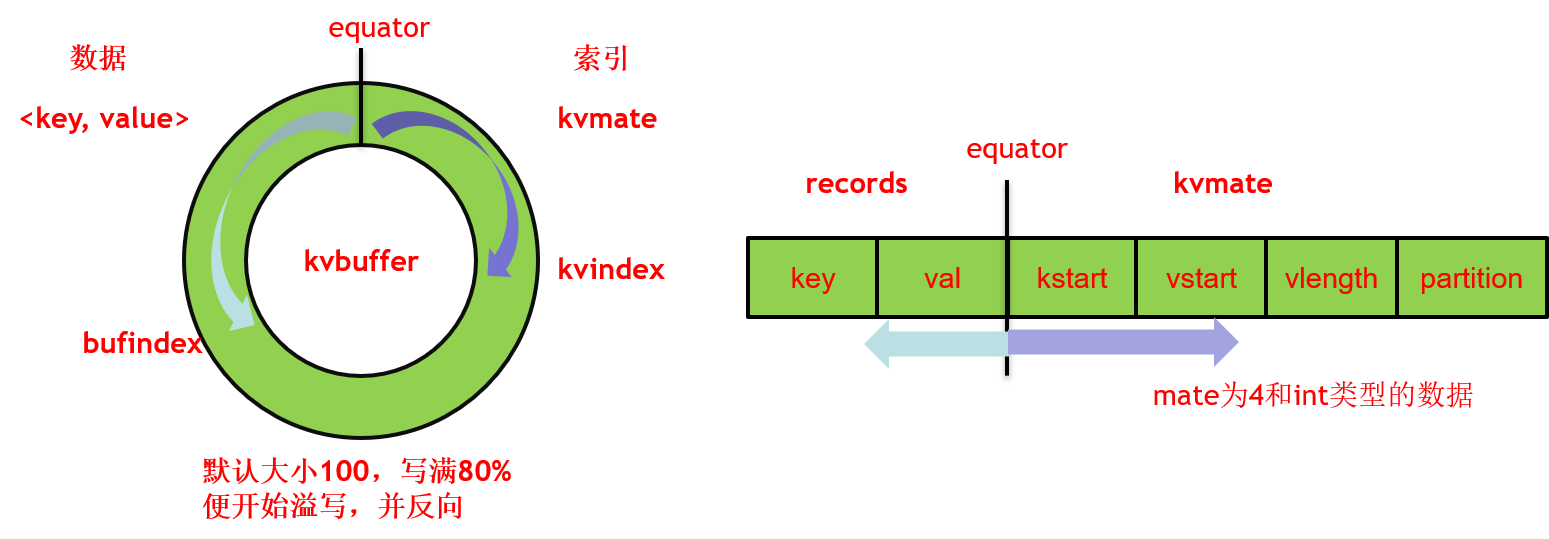
环形缓冲区底层是一个字节数组,首尾相接构成环状,默认大小为100M,当写满80%(默认)时,便开始溢写出小文件。结构图如上图所示,一端储存数据Key-Value键值对,另一端储存数据的索引,索引保存了key的起始位置、value的起始位置、value的长度、partition值,占用四个int长度。
缓冲区采用了典型的单生产者单消费者模式,MapOutputBuffer的collect()方法和MapOutputBuffer.Buffer的write()方法作为生成者,将map端的输出写进缓冲区;spillThread线程作为消费者,将缓冲区中的数据溢写出小文件。其间同步是通过可重入锁spillLock上的两个条件变量spillDone和spillReady实现的。spillDone表示可以从缓冲区溢写文件,spillReady表示溢出准备,可以向缓冲区写入数据。
自定义输入和自定义输出
1)自定义输入:
基础输入抽象类InputFormat两个抽象方法:
getSplits()定义文件的切分规则,并返回切片的集合
createRecordReader()方法,将切片转化为输入的Key-Value键值对,并且返回一个RecordReader。
① 定义自定义的SelfInputFormat类必须继承InputFormat抽象类,并且重写getSplits()方法和重写createRecordReader()方法。
PS:因为一般情况下,没有必要更改文件分片的规则,所以直接继承InputFormat类的实现类FileInputFormat,其中已经实现了文件的分片规则。只需要重写createRecordReader()方法。
② 定义自定义的SelfRecordReader类必须继承RecordReader抽象类,并且重写initialize()、getCurrentKey()、getCurrentValue() 、getProgress()、nextKeyValue(),close()方法。
2)自定义输出:
基础输出抽象类OutputFormat中定义了两个抽象方法 getRecordWriter(),获取这个文件的写入方式;
checkOutputSpecs()检查要写入的文件是否存在。
① 定义自定义的SelfOutputFormat类必须继承OutputFormat抽象类,并且重写getRecordWriter()方法和checkOutputSpecs()方法。
PS:因为一般情况下,没有必要自定义书写路径检查等过程,因此可以直接继承OutputFormat类的实现类FileOutputFormat,它其中已经实现了文件路径的检查等工作;只需要重写getRecordWriter()方法。
② 定义自定义的SelfRecordWriter类必须继承RecordWriter,需要重写writer()方法,定义具体的写入方式和close()方法。
Combiner方法何时被调用
1)Map端,缓冲区数据分区排序后,溢写出小文件前,会自动调用Combiner;
2)缓冲出溢出的多个小文件合并成一个大文件时,会自动调用Combiner;
3)Reduce端,复制map端输出,在合并后溢出到磁盘时,会自动调用Combiner;
分区和分组的区别
分区是将有关联的键划分给同一个Reduce处理,每个分区对应一个Reduce。
分组将相同的键的记录整理成一组记录。在同一个分区里,具有相同的key的记录是在同一组。