回溯搜索算法
回溯搜索算法也就是树形图上的深度优先搜索遍历(DFS),只不过多了一步———状态重置,也是递归算法的运用,正因为递归有“回退”的过程,才可以更好的进行“状态重置”。
可用回溯算法解题的题型:找出所有可能的解。
回溯算法解决问题的特点:解决问题的方法有多种,每种方法又分多步完成,使用深度优先遍历方法得到所有的解。
解题步骤:根据题意画出树形图 -> 分析树形图,找到需要重置的状态变量和找出多余的遍历(剪枝) -> 根据上一步分析的条件,进行深度优先遍历树。
LeetCode T46 全排列
题目描述:给定一个没有重复数字的序列,求序列的全排序。1
2
3
4
5
6
7
8
9
10
11示例:
输入:[1,2,3]
输出:
[
[1, 2, 3],
[1, 3, 2],
[2, 1, 3],
[2, 3, 1],
[3, 1, 2],
[3, 2, 1]
]
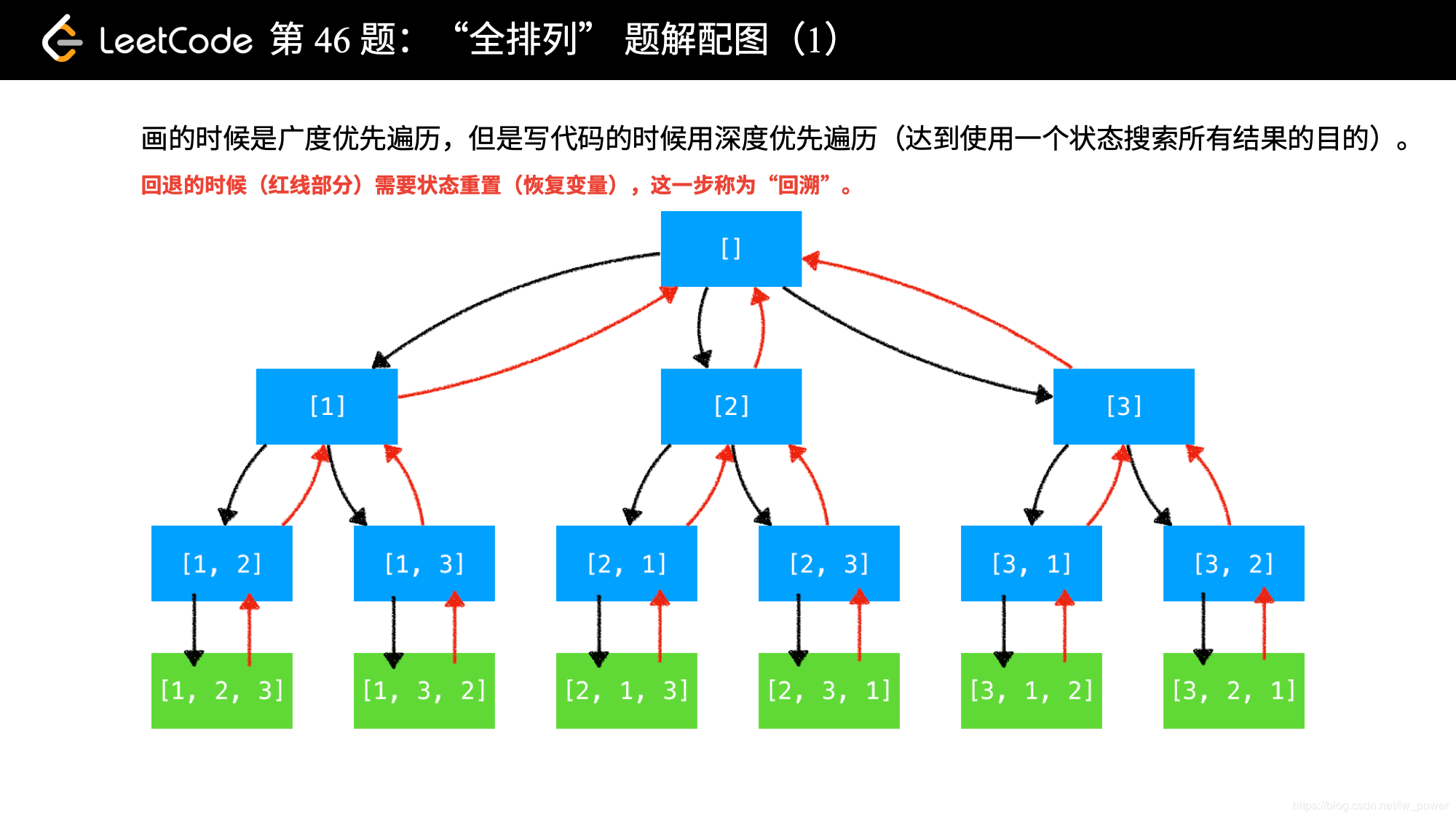
需要设计的状态变量:① 递归树到了几层(已经使用了几个数)depth;② 从跟节点到叶子节点的路径(一个全排列),哪些数是否用过,used。
1 | public List<List<Integer>> permute(int[] nums) { |
LeedCode T47 全排列II
题目描述:给定一个有重复数字的序列,求所有不重复的全排序。1
2
3
4
5
6
7输入: [1, 1, 2]
输出:
[
[1, 1, 2],
[1, 2, 1],
[2, 1, 1]
]
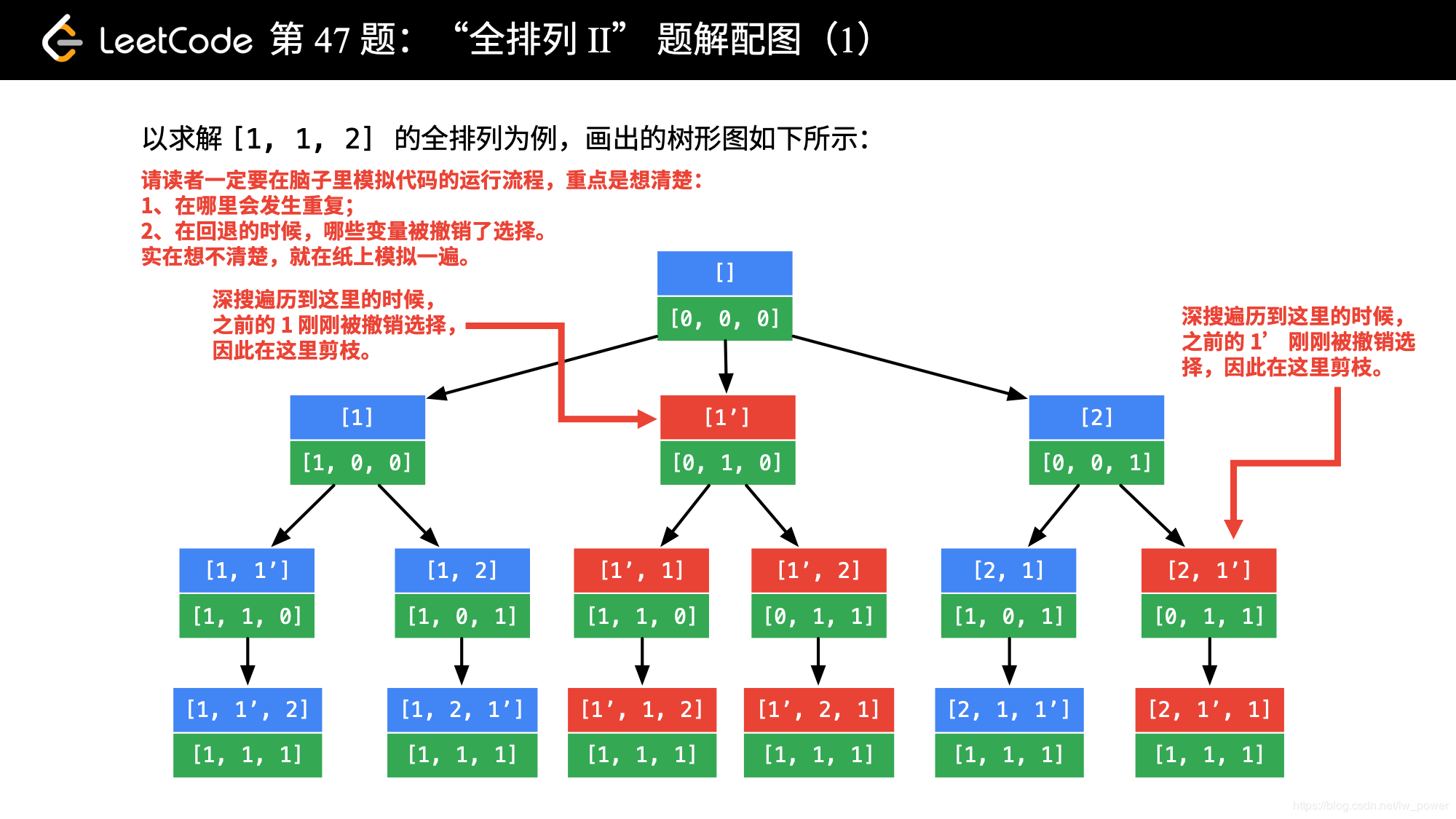
需要设计的转态变量和上一题相同,但需要剪枝 ——— 删除重复的全排列。由上图分析可知,重复发生在,这一轮考虑选择数与上一轮选择的数相同,并且上一轮搜索的那个值因为在回退的过程中,已经被撤销,应该剪去的是这样的枝叶。
1 | public List<List<Integer>> permute(int[] nums) { |
总结:T46和T47类似,T47序列中元素可重复,全排序不可重复,用T46的方法解题,便会产生重复的全排列,因此需要在搜索的过程中进行剪枝操作。遇到元素重复,结果不可重复需要进行剪枝,方法便是判断这一轮考虑选取的数据是否与上一轮的选取的数据相等,相等则跳过。需要剪枝,则对候选序列进行排序,排序的作用:相同的数的索引连续,便于剪枝。
LeetCode T39 组合总和
题目描述:给定一个无重复元素的数组 candidates和一个目标数 target,找出 candidates中所有可以使数字和为 target的组合。candidates中的数字可以无限制重复被选取。解集中不能有重复的组合。1
2
3
4
5
6输入: candidates = [2, 3, 6, 7], target = 7,
所求解集为:
[
[7],
[2, 2, 3]
]
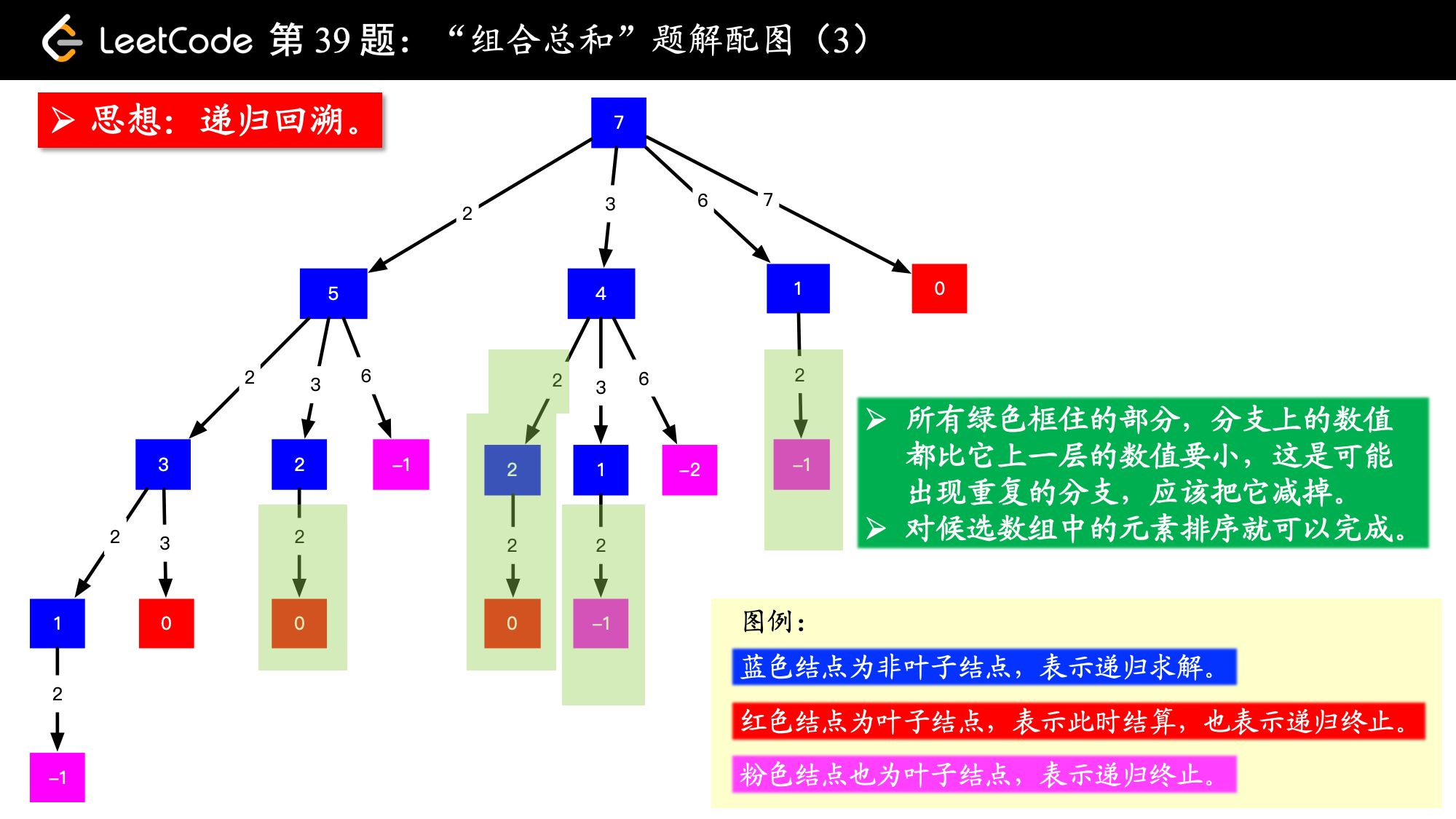
分析树形图,我们可以看到由于较深层次的节点值选取了之前选取过的元素(选出的数相同,只是选取的先后顺序不一样)造成了重复的组合,因此需要设置每一轮搜索的起点。
需要设计的状态量:每一轮需要比较的目标值target;每一轮搜索的起点;
1 | public List<List<Integer>> combinationSum(int[] candidates, int target) { |
LeetCode T40 组合总和II
题目描述:给定一个有重复元素的数组 candidates和一个目标数 target,找出 candidates中所有可以使数字和为 target的组合。candidates中的数字只能选取一次。解集中不能有重复的组合。1
2
3
4
5
6输入: candidates = [2,5,2,1,2], target = 5,
所求解集为:
[
[1, 2, 2],
[5]
]
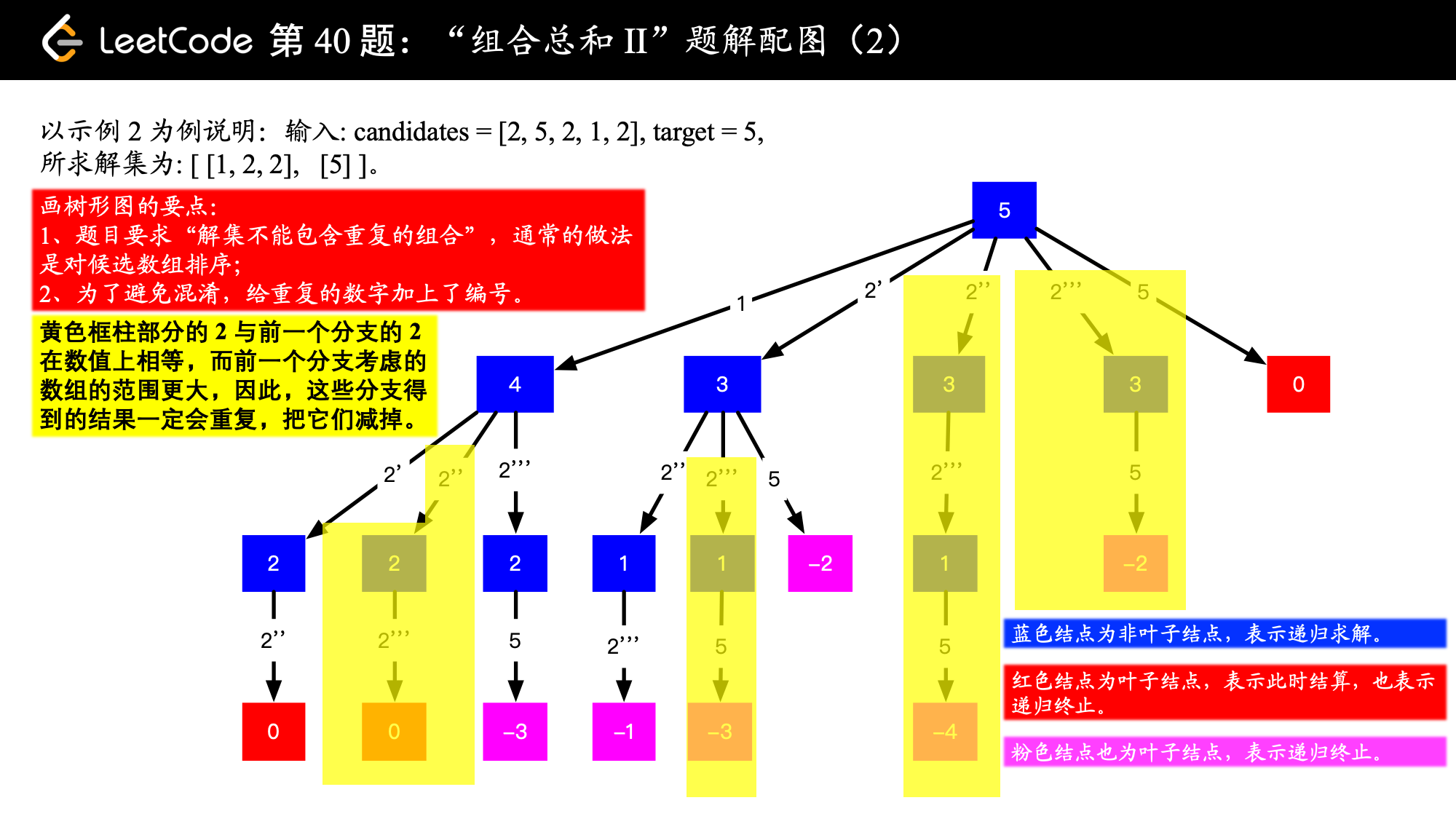
需要设计的状态变量:每一轮需要比较的target值;每一轮的搜索起点。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31public List<List<Integer>> combinationSum2(int[] candidates, int target) {
List<List<Integer>> res = new ArrayList<>();
int len = candidates.length;
if (len == 0) return res;
Arrays.sort(candidates); // 方便剪枝和提前终止循环
dfs(candidates, len, target, 0, new ArrayList<>(), res);
return res;
}
public void dfs(int[] candidates, int len, int target, int begin, List<Integer> path, List<List<Integer>> res) {
if (target == 0) {
res.add(new ArrayList<>(path));
return;
}
// 每次搜索的起点都要比上衣一次大
for (int i = begin; i < len; i++) {
if (target - candidates[i] < 0) {
break;
}
// 这一步之所以能够生效,其前提是数组一定是排好序的;去除重复的路径
// 一定要注意是i > begin 而不是 i > 0
if (i > begin && candidates[i] == candidates[i - 1]) {
continue;
}
path.add(candidates[i]);
// 【关键】因为数组中的数只能使用一次,每轮搜索的起始索引都应该比上一轮的大 i+1
dfs(candidates, len, target - candidates[i], i + 1, path, res);
path.remove(path.size()-1);
}
}
总结:T39和T40的区别是:① 数组元素能否重复取;这点决定每轮搜索的起始索引报不报扩上一轮的搜索起点;能重复,则包括;不能重复则不包括。代码的体现便是,状态变量begin,每次递归传递的是i还是i + 1。
② 数组是否有重复元素;有重复便用排序,再进行剪枝。判断这轮考虑选取的数和上一轮选取数是否相同。
LeetCode T77 组合
题目描述:给定两个整数 n 和 k,返回 1 … n 中所有可能的 k 个数的组合。1
2
3
4
5
6
7
8
9
10输入: n = 4, k = 2
输出:
[
[2,4],
[3,4],
[2,3],
[1,2],
[1,3],
[1,4],
]
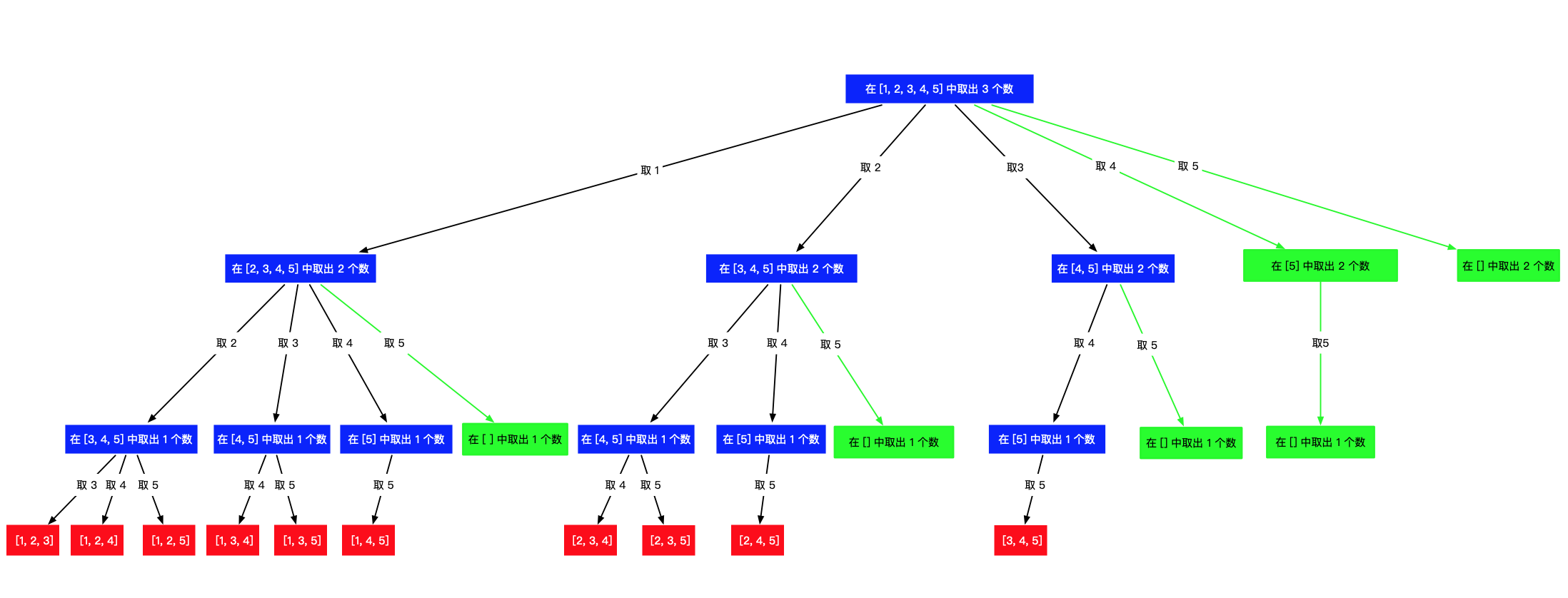
设计状态变量:每轮搜索的起点(数的索引)begin;保存从根节点到叶子节点的路径path;
重点是分析每轮起点能取到的最大值(剪去不必要的循环)。
由上图可知,当path为[1,4,5],[2,4,5],[3,4,5]时,后续的循环就不必要执行。
1 | for (int i = begin; i <= n; i++) { |
上述循环是从[i,n]这个区间里找到k-path.size()个元素,但i<=n不是每次都要循环完,i有上限。
当选定了一个元素,即 path.size() == 1 的时候,接下来要选择 2 个元素,i最大的值是 4 ,因为从 5 开始选择,就无解了;
当选定了两个元素,即path.size() == 2 的时候,接下来要选择 1 个元素, i 最大的值是 5 ,因为从 6 开始选择,就无解了。
再如:如果n = 6 ,k = 4path.size() == 1 的时候,接下来要选择 3 个元素,i 最大的值是 4,最后一个被选的是[4,5,6];path.size() == 2 的时候,接下来要选择 2 个元素,i 最大的值是 5,最后一个被选的是[5,6];path.size() == 3 的时候,接下来要选择 1 个元素,i 最大的值是 6,最后一个被选的是[6];
所以max(i)=n-(k-path.size())+1。
因此,剪枝过程就是:把 i <= n 改成i <= n - (k - path.size()) + 1 。
1 | public List<List<Integer>> res = new ArrayList<>(); |
LeetCode T78 子集
题目描述:给定一组不含重复元素的整数数组 nums,返回该数组所有可能的子集(幂集)。
说明:解集不能包含重复的子集。1
2
3
4
5
6
7
8
9
10
11
12输入: nums = [1,2,3]
输出:
[
[3],
[1],
[2],
[1,2,3],
[1,3],
[2,3],
[1,2],
[]
]
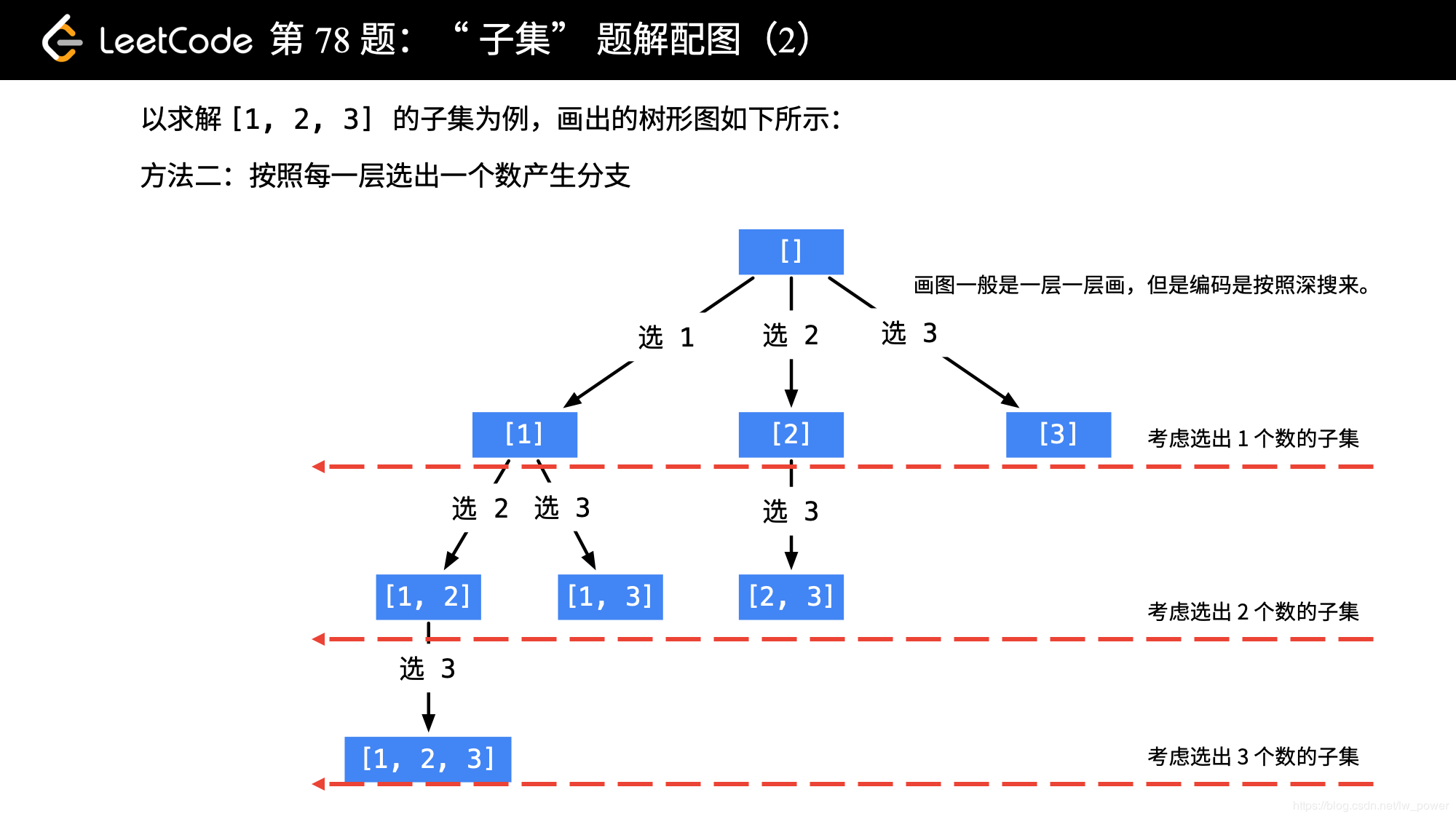
设计状态变量:每轮搜索的起点(数的索引)begin;保存从根节点到叶子节点的路径path;
注意分析每轮起点索引能取到的最大值(剪去不必要的循环),和LeetCode T77 方法相同。
1 | public List<List<Integer>> res = new ArrayList<>(); |
LeetCode T90 子集II
题目描述:给定一组可能包含重复元素的整数数组 nums,返回该数组所有可能的子集(幂集)。
说明:解集不能包含重复的子集。1
2
3
4
5
6
7
8
9
10输入: [1,2,2]
输出:
[
[2],
[1],
[1,2,2],
[2,2],
[1,2],
[]
]

设计状态变量:每轮搜索的起点(数的索引)begin;保存从根节点到叶子节点的路径path;
1 | public List<List<Integer>> res = new ArrayList<>(); |
总结
1)题目规定序列有重复元素,结果输出不重复的组合,先使用排序,使相同元素索引连续,便于剪枝。剪枝的方法是:判断这轮考虑选出的数是否与上一轮选取的数相等。
2)题目规定不能重复使用元素时,需要规定转态变量每轮搜索的起始下标索引。方法是:每轮搜索考虑的下标所以必须必上一轮选取数的下标索引大。
3)题目规定是从序列选取部分数据而不是全部数据时,需要分析循环变量的最大值,最大值为 n - (k - path().size) + 1。