本文就要是介绍三种使用MapReduce方法进行全排序,并比较三种方法的优缺点。
生成测试数据
1 | !/bin/sh |
$RANDOM 是shell内置的变量,生成五位内的随机数。将上述代码保存到iterator.sh文件,并执行下面两个命令,生成两个数据文件,文件内每一行数据便是一个随机数。1
2 sh iteblog.sh > data1
sh iteblog.sh > data2
方法一:使用一个Reduce进行全排序
MapReduce默认就是保证同一个分区内的key有序,但不能保证全局有序,故将所有数据都交给一个Reduce处理,结果就是全部有序。
存在问题:数据量过大时,就会出现OOM问题,也没有体现MapReduce“分而治之”的思想。
代码实现
1 | public class TatalSort1 implements Tool { |
方法二:自定义分区函数实现全排序
Partitioner的作用的对Mapper产生的中间结果进行分片,以便将同一分组的数据交给同一个Reduce处理,Partitioner直接影响Reduce阶段的负载均衡。设置多个分区,key在 0 ~ 10000的数据发送到Reduce 0处理;在10001~20000的数据发送到Reduce 1处理,剩下的发送到Reduce 2进行处理。每一个Reduce处理的结果有序,从而使整个序列有序。
与方法一相比,提高了资源的利用率,但当,key在某一个区间内的数据远远大于其他区间的数据时,就会发生数据倾斜的问题。代码如下:
代码实现
1 | public class TotalSort2 { |
方法三:使用TotalOrderPartioner进行全排序
Hadoop默认分区实现类为HashPartitioner,TotalOrderPartioner也是Hadoop的内置分区实现类,主要用于解决全排序问题。TotalOrderPartitioner能够按照key大小将数据分成若干个区间(分片),并保证后一个区间的所有数据均大于前一个区间的所有数据。分区的分界点由程序决定(比较均匀),方法二的分界点是有人指定的。
全排序的过程:
1. 数据采样。在客户端对待排序的数据进行采样,并对抽样的数据进行排序,产生分割点。Hadoop内置几种采样方法:IntercalSample从s个split里按照一定间隔取样,通常适用于有序数据,效率较随机数据采样器要好一些 ;RandomSample按一定的频率对所有数据做随机采样,效率很低 ;SplitSimpler从s个split里选取前n个记录,效率最高。举例说明:
采样数据为: b, abc, abd, bcd, abcd, efg, hii, afd, rrr, mnk
经排序后获得: abc, abcd, abd, afd, b, bcd, efg, hii, mnk, rrr
若有3个Reduce Task,则采样数据的三等分点 afd, hii 将按照这两个字符串做分割点。
2. Map端对输入的每条数据计算其处在哪两个分割点之间,并对两个分割点之间的数据进行局部排序,将排序后的数据发送到对应ID的Reduce。
PS:如果key(分割点) 的类型是 BinaryComparable (BytesWritable 和Text ),并且 mapreduce.totalorderpartitioner.naturalorder 属性的指是 true ,则会构建trie 树,时间复杂度为O(h),h为树的深度;其他情况会构建一个 BinarySearchNode,用二分查找,时间复杂度为O(log t),t为Reduce Task的个数。
在计算机科学中,trie,又称前缀树或字典树,是一种有序树,用于保存关联数组,其中的键通常是字符串。与二叉查找树不同,键不是直接保存在节点中,而是由节点在树中的位置决定。一个节点的所有子孙都有相同的前缀,也就是这个节点对应的字符串,而根节点对应空字符串。一般情况下,不是所有的节点都有对应的值,只有叶子节点和部分内部节点所对应的键才有相关的值。
假设输入数据汇总的两个字符串“abg”和“mnz”,则字符串“abg”对应partition1;“mnz”对应partition 3。
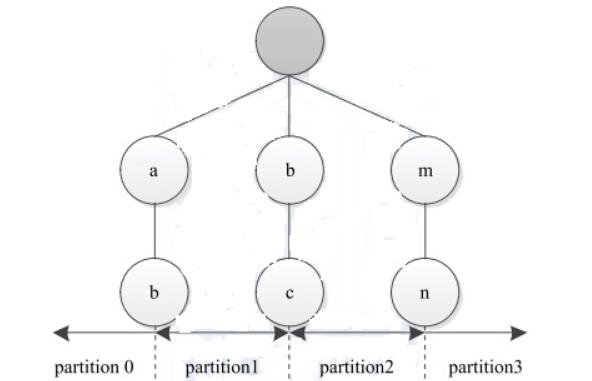
3.Reduce将获得数据直接输出。
代码实现
1 | public class TotalSort3 implements Tool { |
总结
Map端输出的key若为Text类型,Map shuffle中的排序便是按照字典序排序;若为IntWritable/LongWritable类型,则按照大小序排序。KeyValueTextInputFormat将一行数据作为key,是Text类型;默认的TextInputFormat是将每行数据的偏移量作为key,是LongWritable类型。Hadoop在调用map和reduce类时是通过反射来调用的,如果内部类不是静态的,便没有进行类加载,Hadoop便获取不到内部类的实例,出现如下异常:1
java.lang.Exception: java.lang.RuntimeException: java.lang.NoSuchMethodException: TotalSort2$TotalSort2Mapper.<init>()
由于
InputSampler.writePartitionFile()方法实现的原因,必须要求map输入和输出Key的类型一致,否则会出现如下的异常:1
2
3
4
5
6Exception in thread "main" java.io.IOException: wrong key class: org.apache.hadoop.io.Text is not class org.apache.hadoop.io.IntWritable
at org.apache.hadoop.io.SequenceFile$RecordCompressWriter.append(SequenceFile.java:1448)
at org.apache.hadoop.mapreduce.lib.partition.InputSampler.writePartitionFile(InputSampler.java:340)
at TotalSort3.run(TotalSort3.java:57)
at org.apache.hadoop.util.ToolRunner.run(ToolRunner.java:70)
at TotalSort3.main(TotalSort3.java:28)